
Social determinants of health (also known as health-related social needs) have a reliable connection with community and individual-level health outcomes. This is, by and large, a closed issue in healthcare. It’s broadly accepted, heavily studied, and backed by decades of data.
However, a less understood but fascinating part of really digging into SDOH data is how it’s not just a way to understand why people may be facing greater health challenges, but as an additional method to predict those challenges in the first place even without claims data.
We happen to have that social data, so we decided to tackle the question ourselves, and our findings were very compelling. We found with our social data alone and zero clinical insights, we could predict diabetes, obesity, stroke, and depression with high R2 values (77%, 77%, 76%, and 57% respectively).
Let’s get into how we did it, what else we learned, and how it matters for you.
Academic Research and Socially Determined
We’ve spent the past 7+ years working with Virginia Tech’s Computational Modeling and Data Analytics (CMDA) Capstone Program. For the spring 2025 semester, we asked the CMDA program to engage in a problem statement within the field of SDOH: applying our risk scores and social measures to CDC PLACES data to explore the predictive power for population health outcomes. The results were so interesting, McKenna Magoffin, a member of our data science team here at Socially Determined, presented them at the Health Regions SDOH & Place symposium at the University of Illinois Urbana-Champaign's Healthy Regions & Policies Lab.
Can we predict population prevalence of a disease at the ZIP Code level with SDOH data alone?
Our team selected four conditions to test the predictive power of our SDOH data: diabetes, obesity, stroke, and depression, each selected because of their dramatic impact on quality of life, progression of dangerous complications, and prevalence.
The project was set up with the following parameters.
Features with high null rates and highly correlated features were dropped. We used feature engineering to then transform categorical features into numerical values. The scope spread across 32,000 ZIP codes and applied 97 of our SDOH risk and social factor measures as inputs. We tested the predictive power of SDOH at the ZIP Code level and then reviewed the most impactful features for each model. Particularly, here we will discuss the results of the XGBoost model for each health outcome.
The R2 values were as follows:
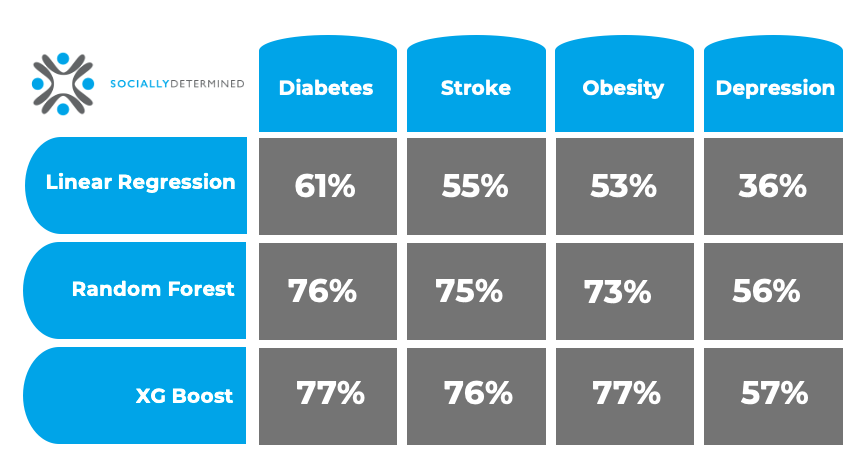
Results: Predicting Stroke, Diabetes, Obesity and Depression with SDOH Data
As we mentioned up top, the results were fascinating. On social risk data alone, without clinical health data, we saw high explainability when predicting population prevalence of diabetes, stroke, obesity, and depression.
Across the health outcomes, we saw health literacy, housing environment, social connectedness, and education features were impactful to the predictions.
Why It Matters: SDOH Interventions
The clinical understanding of social risk’s relationship with health outcomes continues to evolve. What started as a journey to identify the non-clinical factors of life that drive disease progression and costs of care has grown to become a larger factor in public health.
In using social risk data to identify and predict individual health conditions at a high level of accuracy, payers and providers have a new way to understand both the communities they serve and the individual patient story.
In doing so, interventions can be earlier than ever, as well as focused rather than broad spectrum because we didn’t just accurately predict the conditions; we identified the social risk factors associated with each.
These risk factors already have effective interventions, even health literacy by way of nutrition counseling, prenatal health counselling, etc., that can be applied to intervene on the progression of these disease states early and effectively.
Simply having them available generally relies on either effective advertising or awareness campaigns. By knowing precisely who is at risk for what, immediate, proactive conversations from care managers or providers can clear up any patient uncertainty and quickly enroll people where applicable into programs while also arranging any necessary nutrition or transportation support (which each also have a strong, documented impact on care plan adherence and cost savings).
To say we’re proud of our data science team and the students we have the privilege to work with at Virginia Tech is an understatement. It’s an incredible time to work in social determinants of health, and we’re just as excited to share these advancements in data and technology with you.
Come back next week, and we’ll dig a bit deeper into the financial impacts of the data. Until then, if you have any questions, feel free to reach out.